
Selective Regression Testing
Goal and motivation
The purpose of this project is to create and maintain a test system that executes Layout Tests based on code changes, that is, only those tests are selected for execution (automatically) that are affected by the changes made to the source code. The method can be used either in a build bot or as part of an Early Warning System (see SelectiveTestEWS).
The selection is made based on function level code coverage which means that only those tests are selected for a revision x which traverse any of the functions changed at x, all other tests are skipped. Based on an experiments performed on WebKit revisions from October 2011, on average less than 0.1% of the test cases were failing while on average 5 functions were changed per revision in this period. Moreover, the number of test cases affected by a specific change was usually very low. The coverage of all the tests was altogether about 70-75% of the total number of functions but if we perform the tests selectively we can still achieve the same coverage with respect to the changes but by executing only a fraction of all the tests.
In the same experiment, we got a high percentage of inclusiveness: over 95% of the failing test cases in the full test could be identified by using the function change coverage method, and at the same time a significant reduction in the number of tests performed was achieved. Namely, we got this result by executing less than 1% of the test cases on average.
Usage
There will be two types of use of the selective regression tests:
- As a special build bot (currently for the Qt port which started in November 2011). This provides a faster alternative to the build bot performing full test: it saves more than 77% of the total build time including the overhead required for the selection. Probably embedded platforms like ARM could benefit most of this method. The Qt build bot can be found here: http://build.webkit.sed.hu/builders/x86-64%20Linux%20Qt%20Release%20QuickTest
- As part of the official EWS . This will allow developers and reviewers to check the patches in Bugzilla before landing in the repository. Due to the selection the time required to perform the tests will be much less. Detailed description is at SelectiveTestEWS.
Technicalities and how to get it
The method for test selection is the following. We instrument the source code of the methods and functions to log entry and exit events during execution, and make such an instrumented build of the system (using the GCC instrumentation feature and our custom C++ instrumentation code). Then all tests are executed to produce the initial coverage information, which relates each test to a set of functions or methods it executes. This information is stored in a relational database. Next, a set of changed functions is extracted from a revision under test (using an extended PrepareChangeLog script) and this set is used to query the database for a list of tests to execute.
The meta-bug with patches describing the method can be found here: https://bugs.webkit.org/show_bug.cgi?id=78699
Test selection in Selective Regression Testing consists of the following main steps:
- A list of changed methods is determined by Tools/Scripts/prepare-ChangeLog script. This script originally helps the developers to find the locally modified functions when they make their svn comments before an svn commit, and is a simple approximate textual parser. We can get the changed methods with this call: Tools/Scripts/prepare-ChangeLog --no-write 2>&1 | egrep "\(.*\)\:" | sed "s/(g" | sed "s/):g" | sed "s/ /\n/g" (https://bugs.webkit.org/show_bug.cgi?id=78703)
- When the list is ready, a database query is executed to get those test cases which cover the changed methods.
- The result of the query is the list of test cases to be executed, and this list is passed to Tools/Script/run-webkit-tests's --test-list parameter .
Some results
Between November 16, 2011 and April 11, 2012, the Selective Test configuration performed the analysis of 9690 revisions. This corresponds to about 72% of the commits between the revisions r100422 and r113914 (the full test configuration for the same platform analyzed only 6005 revisions in the same period, which means that about 61% more revisions were checked by the Selective Test builder).
The average total time including compilation, test selection and test execution was 1339 seconds for the full test and 287 seconds for the selective test (on an Intel Xeon E5450 3.00GHz machine with 8 cores and 32GiB memory). This means that regression testing errors can be found in about a quarter of time and a higher rate of tested revisions can be obtained, namely without selection only every second of the revisions is tested while with selection 2 of every 3.
Manual investigation of relevant parts of the 9690 revisions has been performed, but we needed a set of revisions shared by both the full and the selective build bots. Because the build queues for the full test and selective test are not synchronized, only 1665 revisions were suitable for comparison. Out of these, 119 revisions had new failures (with a total number of 876 individual failures). Since we limit our analysis to C++ code, we classified the revisions also according to whether they contained C++, non-C++ or mixed changes. Out of the 119, in 5 revisions there were only C++ changes, while 90 revisions were mixed, and the rest contained no C++ changes.
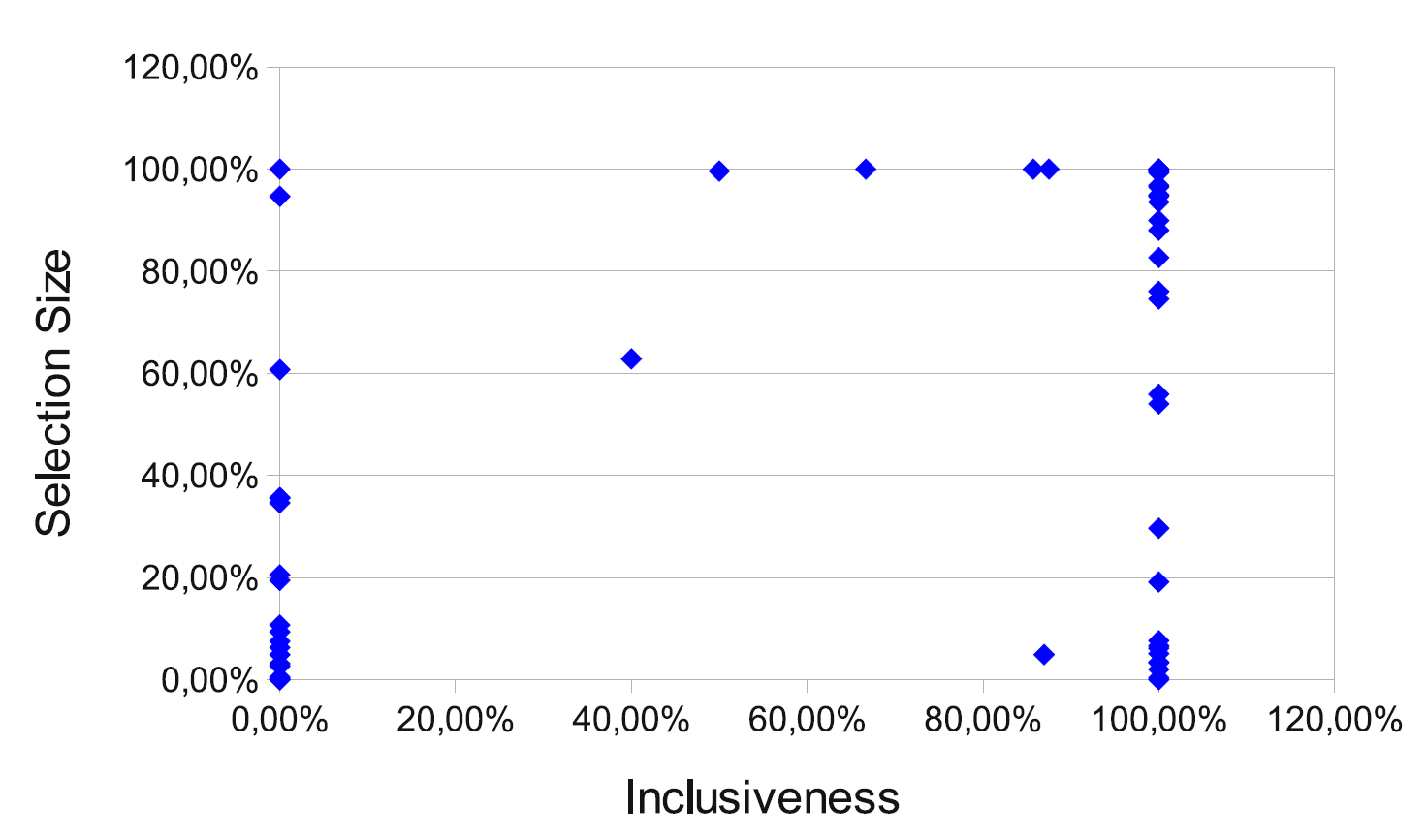
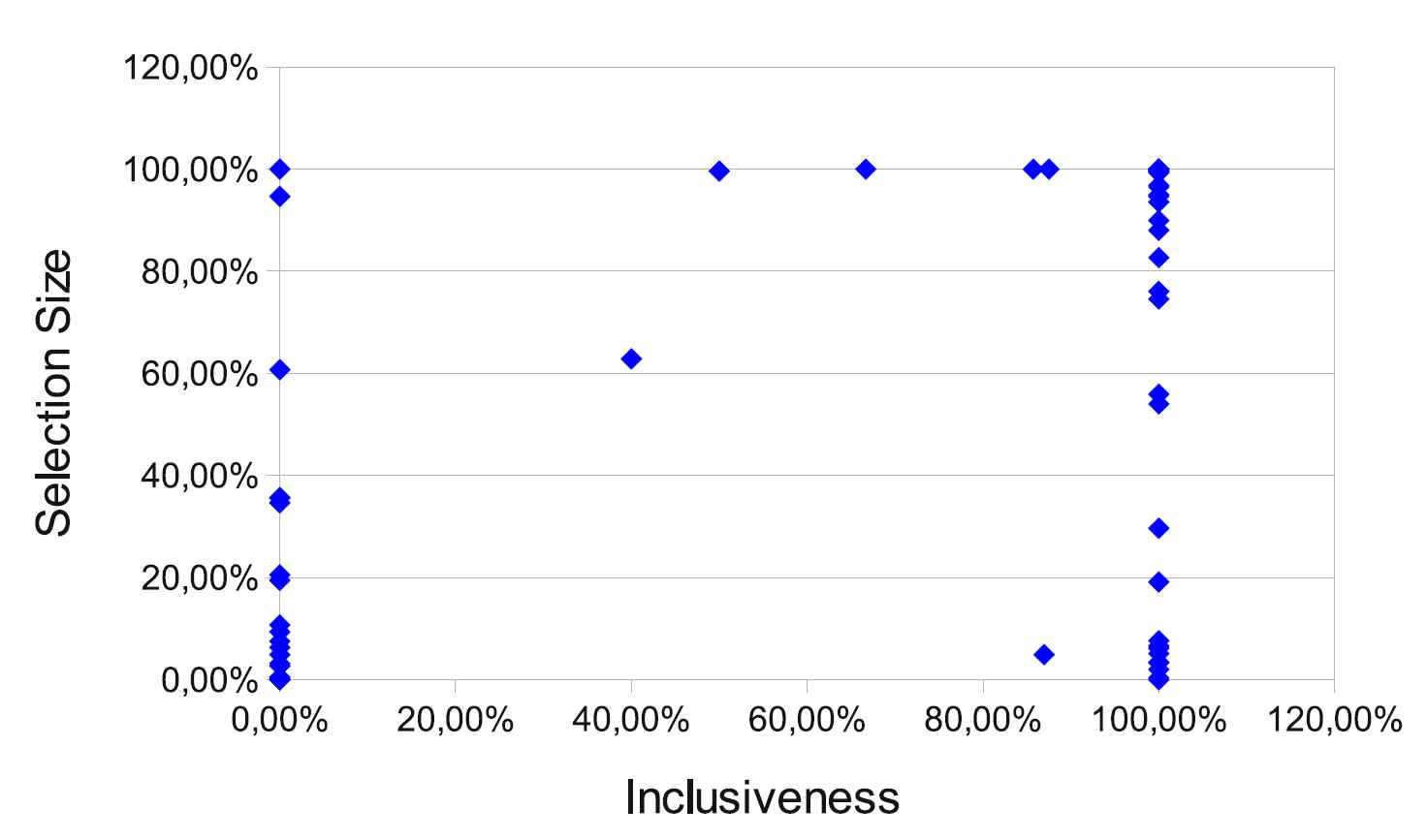
From the C++-only revisions there was a build problem with one of them, but in the remaining 4 revisions the selective test captured all failures (30 altogether) of the full test (inclusiveness was 100%). In the mixed revisions, from the total 302 failures 60% (181) was correctly identified.
The selection capabilities for the remaining ca. 8000 revisions were checked by performing the selection offline in a batch process specifically created for this purpose. For this, we used the same coverage database, list of changes and set of tools as the Selective Test bot uses. We also limited the analysis to those revisions that contained changes to C++ code only, and looked only at new failures in the revisions. The overall inclusiveness we got was 75.38% in this case. Most of the missed failures by the selective test could be attributed to changes in some non-C++ code, which we cannot handle currently, to the slightly outdated coverage database and the imperfections of the change determination method.
The selection size (number of selected tests) varied: there were many small (0 or 1) but also complete (almost all tests) selections. The following graph shows the relationship between the inclusiveness and selection size. As can be seen, there are several cases when the selection size is big. Currently, we are working on prioritization algorithms to further reduce the selection size.

Attachments (2)
- selectivetest.png (54.4 KB ) - added by 14 years ago.
- selectivetest.jpg (40.5 KB ) - added by 14 years ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip