
| Version 2 (modified by , 14 years ago) ( diff ) |
|---|
Selective Regression Testing
Goal
The purpose of this project is to create and maintain a test system that executes Layout Tests based on code changes, that is, only those tests are selected for execution (automatically) that are affected by the changes made to the source code. The method can be used either in a build bot or as part of an Early Warning System (see SelectiveTestEWS).
Motivation
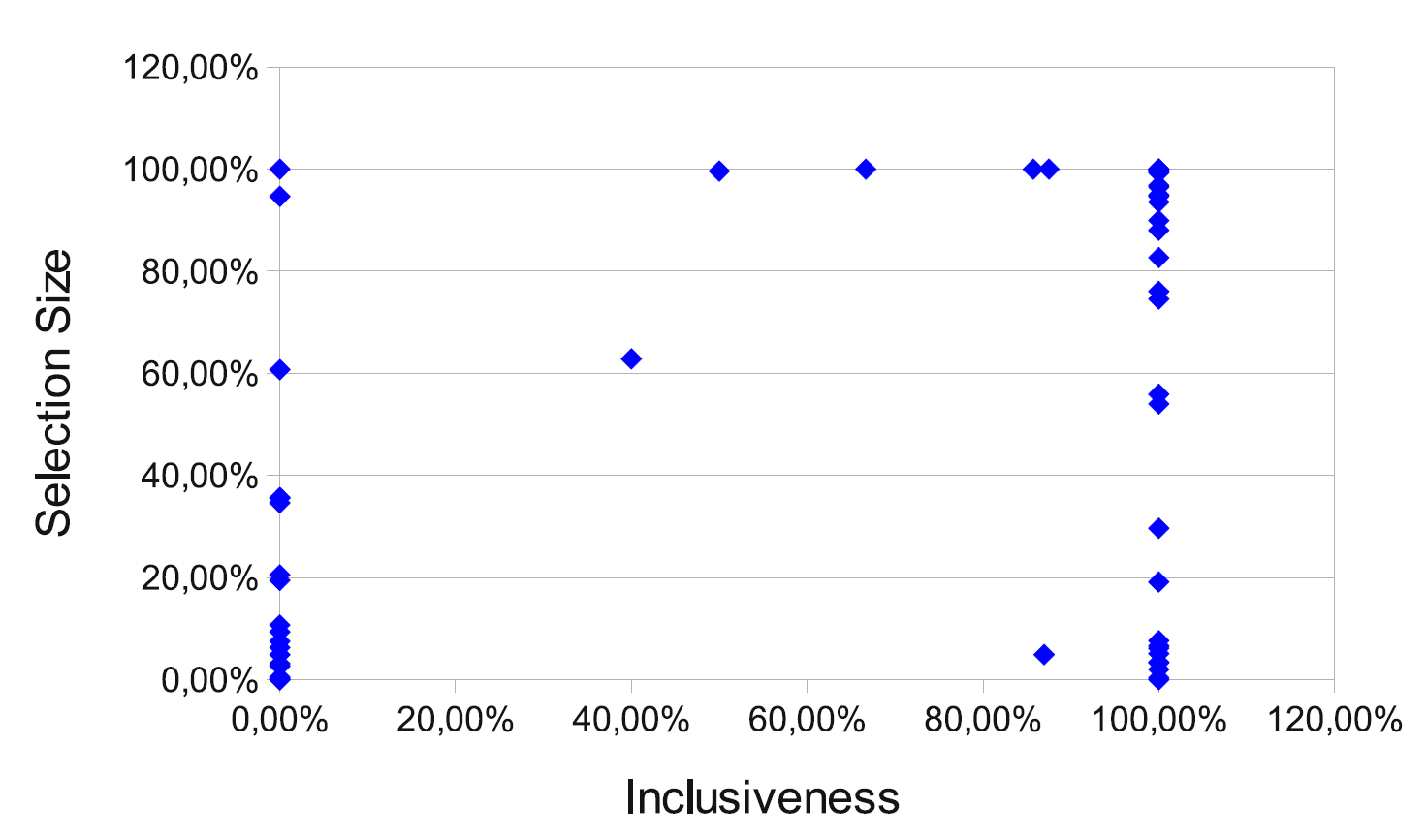
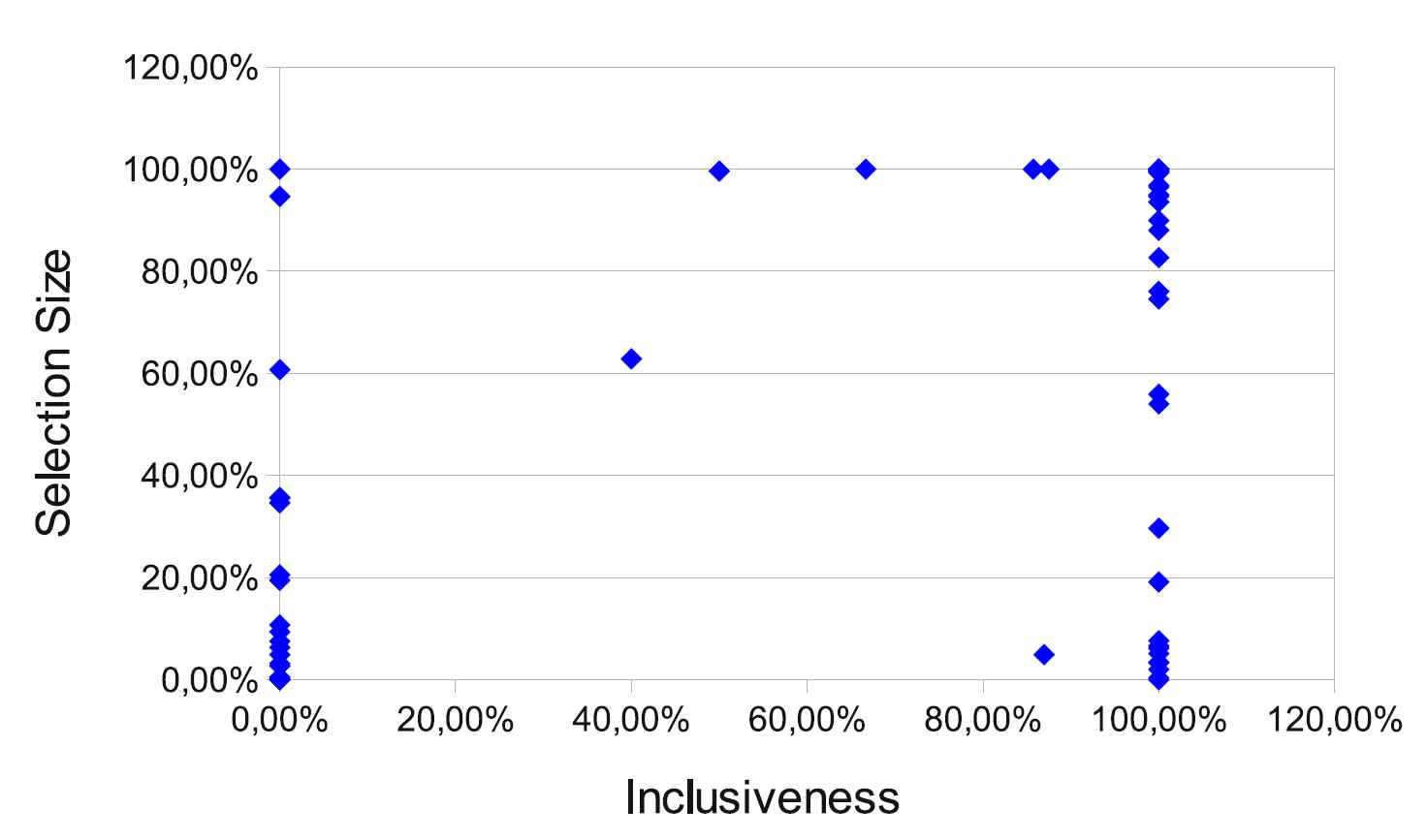
The selection is made based on function level code coverage which means that only those tests are selected for a revision x which traverse any of the functions changed at x, all other tests are skipped. Based on an experiments performed on WebKit revisions from October 2011, on average less than 0.1% of the test cases were failing while on average 5 functions were changed per revision in this period. Moreover, the number of test cases affected by a specific change was usually very low. The coverage of all the tests was altogether about 70-75% of the total number of functions but if we perform the tests selectively we can still achieve the same coverage with respect to the changes but by executing only a fraction of all the tests.
In the same experiment, we got a high percentage of inclusiveness: over 95% of the failing test cases in the full test could be identified by using the function change coverage method, and at the same time a siginficant reduction in the number of test performed was achieved. Namely, we got this result by executing less than 1% of the test cases on average.
Technicalities
The method for test selection is the following. We instrument the source code of the methods and functions to log entry and exit events during execution, and make such an instrumented build of the system. Then all tests are executed to produce the initial coverage information, which relates each test to a set of functions it executes. This information is stored in a relational database. Next, a set of changed functions is extracted from a revision under test and this set is used to query the database for a list of tests to execute. The technical details and source code of the scripts can be found at RegSelectionDetails.
Usage
There will be two types of use of the selective regression tests:
- As a special build bot (currently for the Qt port). This provides a faster alternative to the build bot performing full test: it saves more than 77% of the total build time including the overhead required for the selection.
- As part of the Chromium Early Warning System. This will allow developers and reviewers to check the patches in Bugzilla before landing in the repository. Due to the selection the time required to perform the tests will be much less. Detailed description is at SelectiveTestEWS.
Build bot
The selective test build bot for Qt has been started in November 2011, and since then several hundred builds have been performed. Technical details can be found at SelectiveTestTechnical.
Initial analysis of results
This bot is running in parallel to the full Qt test, but since both bots usually have to skip revisions there was only 64 revisions that were common. We manually compared the full and selective test for the inclusivenes of the selection:
- We excluded contiguous failing tests because the selective test looks only for changes and does not deal with reoccuring failures.
- There were 5 Crashes among these revisions
- In 9 cases exactly the same test cases were failing in the two bots
- There were additional failures in both bots in 24 cases
- In 3 cases there were tests that the selective test did not find
- In 23 cases selective test found more failures
Overall, in the cases where there was an overlap between the failures found, about 77% of the failures in the full test have been found by the selective test. The majority of the additional failures not found by the full test turned out to be flakes or time outs. Among the missed failures by the selective test 92% was due to the outdated coverage database (some new tests were not in it yet) and the rest is due to flakes and time outs.
Since the coverage computation is resource intensive operation we plan to update the coverage database on a regular basis but not for each revision. This will then eliminate most of the remaining 23% of the missed failures. Currently we are working on starting a continuous (instrumented) build bot to provide mostly up to date coverage information.
Attachments (2)
- selectivetest.png (54.4 KB ) - added by 14 years ago.
- selectivetest.jpg (40.5 KB ) - added by 14 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip